Facial Expression Challenge
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from bokeh.plotting import figure , show
from bokeh.io import output_notebook
import random
matplotlib . style . use ( 'ggplot' )
% matplotlib inline
Describe the Data
df = pd . read_csv ( "training/fer2013.csv" )
print ( df . head ())
print ( "Number of unique Emotions: % s" % ( df . emotion . unique ()))
emotion pixels Usage
0 0 70 80 82 72 58 58 60 63 54 58 60 48 89 115 121... Training
1 0 151 150 147 155 148 133 111 140 170 174 182 15... Training
2 2 231 212 156 164 174 138 161 173 182 200 106 38... Training
3 4 24 32 36 30 32 23 19 20 30 41 21 22 32 34 21 1... Training
4 6 4 0 0 0 0 0 0 0 0 0 0 0 3 15 23 28 48 50 58 84... Training
Number of unique Emotions: [0 2 4 6 3 5 1]
Helper Functions
# pixels is the series from the Dataframe
def extract_from_string ( pixels ):
pixels = pixels . split ( ' ' )
pixels = np . array ([ int ( i ) for i in pixels ])
return np . reshape ( pixels , ( 48 , 48 ))
def extract_image ( pixels ):
pixels = pixels . as_matrix ()[ 0 ] # The output is a string
return extract_from_string ( pixels )
Overview of the images
def overview ( total_rows , df ):
fig = plt . figure ( figsize = ( 8 , 10 ))
idx = 0
for i , row in df . iterrows ():
input_img = extract_from_string ( row . pixels )
ax = fig . add_subplot ( 16 , 12 , idx + 1 )
ax . imshow ( input_img , cmap = matplotlib . cm . gray )
plt . xticks ( np . array ([]))
plt . yticks ( np . array ([]))
plt . tight_layout ()
idx += 1
plt . show ()
num_images = 191
df = df . sample ( n = num_images )
overview ( num_images , df ) # overview of face data as thumbnails (private)
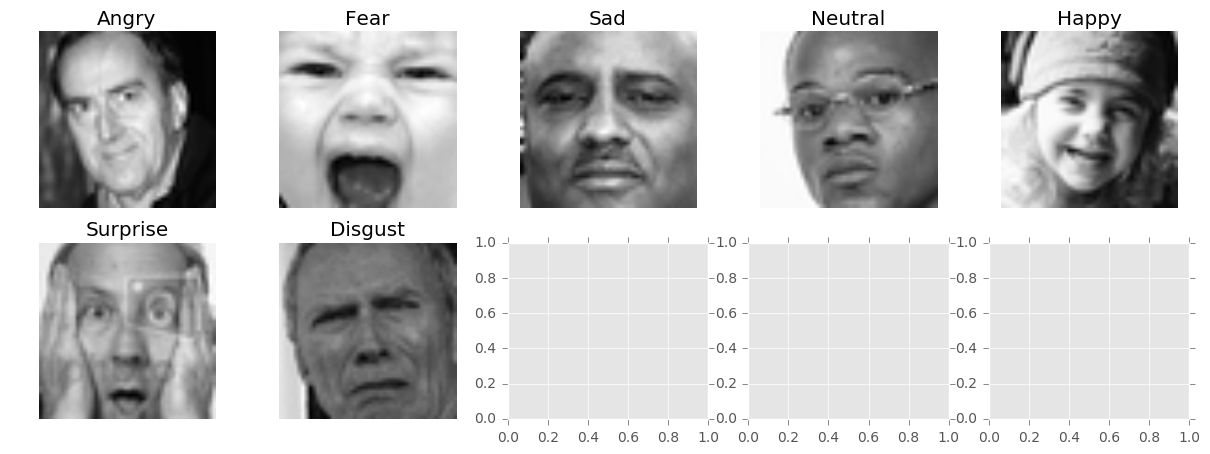
Display one unique Emotion
emotion_description = { 0 : "Angry" , 1 : "Disgust" , 2 : "Fear" , 3 : "Happy" , 4 : "Sad" , 5 : "Surprise" , 6 : "Neutral" }
unique_emotions = df . emotion . unique ()
images = []
emotions = []
for emotion in unique_emotions :
emotion_df = df [ df . emotion == emotion ] . sample ( n = 1 )
images . append ( extract_image ( emotion_df . pixels ))
emotions . append ( emotion )
cols = 5
fig , ax = plt . subplots ( len ( images ) // cols + 1 , cols , figsize = ( 15 , 5 ))
global_img = None
for i , img in enumerate ( images ):
row = i // cols
col = i % cols
ax [ row , col ] . imshow ( img , cmap = 'gray' )
ax [ row , col ] . axis ( 'off' )
ax [ row , col ] . set_title ( emotion_description [ emotions [ i ]])
global_img = img
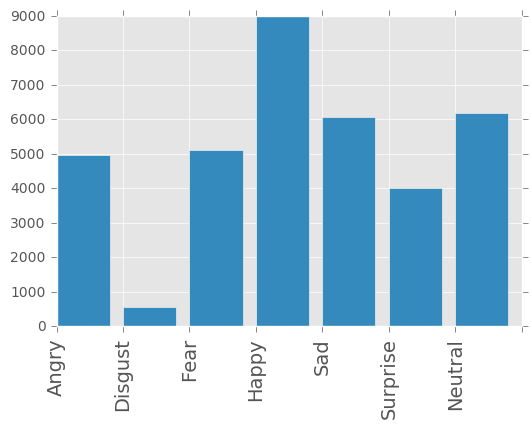
Data Distribution
value_counts = df [ 'emotion' ] . value_counts () . sort_index ()
ax = plt . subplot ()
x_ticks_labels = [ emotion_description [ i ] for i in range ( len ( value_counts ))]
ax . set_xticklabels ( x_ticks_labels , rotation = 'vertical' , fontsize = 14 )
ax . bar ( range ( 0 , len ( value_counts )), value_counts )
print ( value_counts )
0 4953
1 547
2 5121
3 8989
4 6077
5 4002
6 6198
Name: emotion, dtype: int64
Use Image Augmentation to Augment the dataset
from scipy import ndimage
from scipy.misc import imresize
from skimage import data , io , filters
from skimage.transform import swirl
import cv2
Image Augmentation Techniques
def display_side_by_side ( img1 , img2 ):
fig , ax = plt . subplots ( 1 , 2 )
ax [ 0 ] . imshow ( img1 , cmap = 'gray' )
ax [ 0 ] . axis ( 'off' )
ax [ 1 ] . imshow ( img2 , cmap = 'gray' )
ax [ 1 ] . axis ( 'off' )
def ogrid ( img ):
nimg = np . copy ( img )
lx , ly = nimg . shape
X , Y = np . ogrid [ 0 : lx , 0 : ly ]
mask = ( X - lx / 2 ) ** 2 + ( Y - ly / 2 ) ** 2 > lx * ly / 4
nimg [ mask ] = 0
return nimg
nimg = ogrid ( global_img )
display_side_by_side ( global_img , nimg )
def rotate_img ( img ):
angle = np . random . choice ( np . random . uniform ( - 45 , 45 , 100 ))
nimg = np . copy ( img )
nimg = ndimage . rotate ( nimg , angle )
height , width = img . shape
nimg = imresize ( nimg , ( width , height ))
return nimg
nimg = rotate_img ( global_img )
display_side_by_side ( global_img , nimg )
def blur_img ( img ):
nimg = np . copy ( img )
sigma = np . random . randint ( 1 , 2 )
blurred_img = ndimage . gaussian_filter ( nimg , sigma = sigma )
return blurred_img
nimg = blur_img ( global_img )
display_side_by_side ( global_img , nimg )
def flip_img ( img ):
nimg = np . copy ( img )
nimg = np . fliplr ( nimg )
return nimg
nimg = flip_img ( global_img )
display_side_by_side ( global_img , nimg )
def add_noise ( img ):
nimg = np . copy ( img )
noise = np . random . normal ( 0 , 0.5 , size = ( 48 , 48 )) . astype ( np . uint8 ) * 255
nimg += noise
nimg = np . clip ( nimg , 0 , 255 )
return nimg
nimg = add_noise ( global_img )
display_side_by_side ( global_img , nimg )
def augment_img ( img ):
methods = [ ogrid , rotate_img , blur_img , flip_img , add_noise ]
method = np . random . choice ( methods )
return method ( img )
max_value = df [ 'emotion' ] . value_counts () . max ()
max_idx = df [ 'emotion' ] . value_counts () . idxmax ()
print ( max_idx , max_value )
Convert the pixels from the Dataframe into actual images
new_df = pd . DataFrame ()
for i , row in df . iterrows ():
# Take this row and convert its pixel type to actual image
new_df = new_df . append ( pd . Series ([ row . emotion , extract_from_string ( row . pixels ), row . Usage ], index = [ 'emotion' , 'pixels' , 'Usage' ], name = str ( i )))
print ( new_df )
Usage emotion pixels
0 Training 0.0 [[70, 80, 82, 72, 58, 58, 60, 63, 54, 58, 60, ...
1 Training 0.0 [[151, 150, 147, 155, 148, 133, 111, 140, 170,...
2 Training 2.0 [[231, 212, 156, 164, 174, 138, 161, 173, 182,...
3 Training 4.0 [[24, 32, 36, 30, 32, 23, 19, 20, 30, 41, 21, ...
4 Training 6.0 [[4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 15, 2...
5 Training 2.0 [[55, 55, 55, 55, 55, 54, 60, 68, 54, 85, 151,...
6 Training 4.0 [[20, 17, 19, 21, 25, 38, 42, 42, 46, 54, 56, ...
7 Training 3.0 [[77, 78, 79, 79, 78, 75, 60, 55, 47, 48, 58, ...
8 Training 3.0 [[85, 84, 90, 121, 101, 102, 133, 153, 153, 16...
9 Training 2.0 [[255, 254, 255, 254, 254, 179, 122, 107, 95, ...
10 Training 0.0 [[30, 24, 21, 23, 25, 25, 49, 67, 84, 103, 120...
11 Training 6.0 [[39, 75, 78, 58, 58, 45, 49, 48, 103, 156, 81...
12 Training 6.0 [[219, 213, 206, 202, 209, 217, 216, 215, 219,...
13 Training 6.0 [[148, 144, 130, 129, 119, 122, 129, 131, 139,...
14 Training 3.0 [[4, 2, 13, 41, 56, 62, 67, 87, 95, 62, 65, 70...
15 Training 5.0 [[107, 107, 109, 109, 109, 109, 110, 101, 123,...
16 Training 3.0 [[14, 14, 18, 28, 27, 22, 21, 30, 42, 61, 77, ...
17 Training 2.0 [[255, 255, 255, 255, 255, 255, 255, 255, 255,...
18 Training 6.0 [[134, 124, 167, 180, 197, 194, 203, 210, 204,...
19 Training 4.0 [[219, 192, 179, 148, 208, 254, 192, 98, 121, ...
20 Training 4.0 [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2,...
21 Training 2.0 [[174, 51, 37, 37, 38, 41, 22, 25, 22, 24, 35,...
22 Training 0.0 [[123, 125, 124, 142, 209, 226, 234, 236, 231,...
23 Training 0.0 [[8, 9, 14, 21, 26, 32, 37, 46, 52, 62, 72, 70...
24 Training 3.0 [[252, 250, 246, 229, 182, 140, 98, 72, 53, 44...
25 Training 3.0 [[224, 227, 219, 217, 215, 210, 187, 177, 189,...
26 Training 5.0 [[162, 200, 187, 180, 197, 198, 196, 192, 176,...
27 Training 0.0 [[236, 230, 225, 226, 228, 209, 199, 193, 196,...
28 Training 3.0 [[210, 210, 210, 210, 211, 207, 147, 103, 68, ...
29 Training 5.0 [[50, 44, 74, 141, 187, 187, 169, 113, 80, 128...
... ... ... ...
35857 PrivateTest 5.0 [[253, 255, 229, 150, 89, 61, 54, 60, 55, 49, ...
35858 PrivateTest 4.0 [[11, 11, 11, 13, 20, 27, 38, 41, 38, 34, 20, ...
35859 PrivateTest 4.0 [[11, 13, 16, 27, 24, 26, 89, 161, 190, 197, 2...
35860 PrivateTest 3.0 [[27, 42, 62, 91, 112, 118, 122, 123, 119, 124...
35861 PrivateTest 6.0 [[233, 232, 208, 188, 194, 179, 177, 167, 157,...
35862 PrivateTest 2.0 [[73, 54, 63, 76, 82, 71, 67, 69, 73, 72, 92, ...
35863 PrivateTest 5.0 [[196, 196, 197, 197, 198, 198, 198, 196, 176,...
35864 PrivateTest 4.0 [[68, 59, 65, 78, 118, 131, 137, 141, 142, 135...
35865 PrivateTest 3.0 [[102, 109, 109, 106, 104, 107, 112, 109, 116,...
35866 PrivateTest 6.0 [[87, 82, 59, 61, 72, 102, 143, 130, 90, 95, 1...
35867 PrivateTest 3.0 [[198, 198, 197, 196, 196, 197, 196, 196, 196,...
35868 PrivateTest 2.0 [[204, 209, 215, 218, 214, 214, 214, 217, 205,...
35869 PrivateTest 3.0 [[217, 220, 222, 223, 223, 224, 225, 223, 223,...
35870 PrivateTest 2.0 [[6, 8, 4, 5, 30, 48, 61, 70, 76, 79, 98, 117,...
35871 PrivateTest 6.0 [[112, 102, 98, 89, 98, 133, 164, 185, 180, 17...
35872 PrivateTest 5.0 [[131, 159, 90, 59, 10, 0, 1, 1, 1, 0, 1, 1, 0...
35873 PrivateTest 4.0 [[54, 57, 77, 122, 121, 76, 73, 80, 58, 22, 26...
35874 PrivateTest 5.0 [[43, 43, 51, 73, 94, 97, 102, 95, 99, 107, 12...
35875 PrivateTest 5.0 [[248, 251, 239, 144, 102, 95, 82, 77, 91, 138...
35876 PrivateTest 6.0 [[29, 29, 27, 31, 49, 56, 29, 19, 22, 20, 34, ...
35877 PrivateTest 6.0 [[139, 143, 145, 154, 159, 168, 176, 181, 190,...
35878 PrivateTest 3.0 [[0, 39, 81, 80, 104, 97, 51, 64, 68, 46, 41, ...
35879 PrivateTest 2.0 [[0, 0, 6, 16, 19, 31, 47, 18, 26, 19, 17, 8, ...
35880 PrivateTest 2.0 [[164, 172, 175, 171, 172, 173, 178, 181, 188,...
35881 PrivateTest 0.0 [[181, 177, 176, 156, 178, 144, 136, 132, 122,...
35882 PrivateTest 6.0 [[50, 36, 17, 22, 23, 29, 33, 39, 34, 37, 37, ...
35883 PrivateTest 3.0 [[178, 174, 172, 173, 181, 188, 191, 194, 196,...
35884 PrivateTest 0.0 [[17, 17, 16, 23, 28, 22, 19, 17, 25, 26, 20, ...
35885 PrivateTest 3.0 [[30, 28, 28, 29, 31, 30, 42, 68, 79, 81, 77, ...
35886 PrivateTest 2.0 [[19, 13, 14, 12, 13, 16, 21, 33, 50, 57, 71, ...
[35887 rows x 3 columns]
Make all the Image categories the same size
augmented_df = new_df . copy ()
unique_emotions = new_df . emotion . unique ()
for emotion in unique_emotions :
if emotion != max_idx :
# This is the dataset we want to augment
# Find the current length of this emotion
emotion_df = augmented_df [ augmented_df . emotion == emotion ]
current_size = len ( emotion_df )
images_2_generate = max_value - current_size
for i in range ( 0 , images_2_generate ):
# Choose a random image
emotion_df = augmented_df [ augmented_df . emotion == emotion ] . sample ( n = 1 )
current_img = emotion_df . pixels [ 0 ]
nimg = augment_img ( current_img )
# Add a new row
row = pd . Series ([ emotion , nimg , "Training" ], index = [ "emotion" , "pixels" , "Usage" ], name = str ( i ))
augmented_df = augmented_df . append ( row )
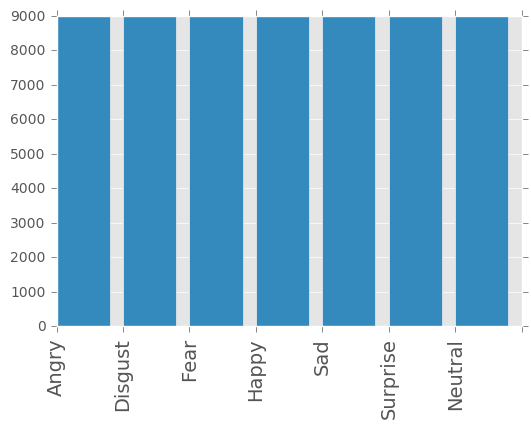
New Data Distribution
value_counts = augmented_df [ 'emotion' ] . value_counts () . sort_index ()
ax = plt . subplot ()
x_ticks_labels = [ emotion_description [ i ] for i in range ( len ( value_counts ))]
ax . set_xticklabels ( x_ticks_labels , rotation = 'vertical' , fontsize = 14 )
ax . bar ( range ( 0 , len ( value_counts )), value_counts )
print ( value_counts )
0.0 8989
1.0 8989
2.0 8989
3.0 8989
4.0 8989
5.0 8989
6.0 8989
Name: emotion, dtype: int64
Network
from keras.models import Sequential
from keras.layers import Dense , Dropout , Flatten , BatchNormalization , Lambda , Activation
from keras.layers import Conv2D , MaxPooling2D , concatenate , Input
from keras.callbacks import TensorBoard
from keras.models import load_model , Model
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import ModelCheckpoint
from keras_tqdm import TQDMNotebookCallback
from keras.utils import np_utils
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
class LeNet :
@staticmethod
def build ( width , height , depth , classes , weightsPath = None ):
model = Sequential ()
# First set Conv Layers
model . add ( Conv2D ( 64 , ( 3 , 3 ), padding = 'valid' , input_shape = ( width , height , depth ), activation = 'relu' ))
model . add ( MaxPooling2D ( pool_size = ( 2 , 2 ), strides = ( 2 , 2 )))
model . add ( BatchNormalization ())
# 2nd set Conv layers
model . add ( Conv2D ( 128 , ( 3 , 3 ), padding = 'valid' , input_shape = ( width , height , depth ), activation = 'relu' ))
model . add ( MaxPooling2D ( pool_size = ( 2 , 2 ), strides = ( 2 , 2 )))
model . add ( BatchNormalization ())
model . add ( Conv2D ( 256 , ( 3 , 3 ), padding = 'valid' , activation = 'relu' ))
model . add ( MaxPooling2D ( pool_size = ( 2 , 2 ), strides = ( 2 , 2 )))
model . add ( BatchNormalization ())
model . add ( Conv2D ( 512 , ( 3 , 3 ), padding = 'valid' , activation = 'relu' ))
model . add ( MaxPooling2D ( pool_size = ( 2 , 2 ), strides = ( 2 , 2 )))
model . add ( BatchNormalization ())
model . add ( Dropout ( 0.5 ))
# Set of FC => Relu layers
model . add ( Flatten ())
model . add ( Dense ( 256 ))
model . add ( Activation ( 'relu' ))
model . add ( Dropout ( 0.5 ))
# Softmax classifier
model . add ( Dense ( classes ))
model . add ( Activation ( 'softmax' ))
if weightsPath is not None :
model . load_weights ( weightsPath )
return model
model = LeNet . build ( 48 , 48 , 1 , 7 )
model . compile ( loss = 'categorical_crossentropy' , optimizer = 'adam' , metrics = [ 'accuracy' ])
generator = ImageDataGenerator ( featurewise_center = True ,
samplewise_center = False ,
featurewise_std_normalization = False ,
samplewise_std_normalization = False ,
zca_whitening = False ,
rotation_range = 20. ,
width_shift_range = 0.4 ,
height_shift_range = 0.4 ,
shear_range = 0.2 ,
zoom_range = 0.2 ,
channel_shift_range = 0.1 ,
fill_mode = 'nearest' ,
horizontal_flip = True ,
vertical_flip = False ,
rescale = 1.2 ,
preprocessing_function = None )
train_df = augmented_df [ augmented_df . Usage == "Training" ]
test_df = augmented_df [ augmented_df . Usage == "PrivateTest" ]
trainData = np . array ( train_df . pixels , dtype = pd . Series )
trainLabels = np . array ( train_df . emotion , dtype = pd . Series )
trainLabels = np_utils . to_categorical ( trainLabels , 7 )
testData = np . array ( train_df . pixels , dtype = pd . Series )
testLabels = np . array ( train_df . emotion , dtype = pd . Series )
testLabels = np_utils . to_categorical ( testLabels , 7 )
td = []
for t in trainData :
t = np . reshape ( t , ( 48 , 48 , 1 ))
td . append ( t )
tl = []
for t in trainLabels :
tl . append ( t )
trainData = np . array ( td )
trainLabels = np . array ( tl )
trainData , trainLabels = shuffle ( trainData , trainLabels )
td = []
for t in testData :
t = np . reshape ( t , ( 48 , 48 , 1 ))
td . append ( t )
tl = []
for t in testLabels :
tl . append ( t )
testData = np . array ( td )
testLabels = np . array ( tl )
generator . fit ( trainData )
filepath = "lenet.best.h5"
checkpoint = ModelCheckpoint ( filepath , monitor = 'val_acc' , verbose = 1 , save_best_only = True , mode = 'max' )
batch_size = 128
use_augmentation = False
if use_augmentation :
trainData , validationData , trainLabels , validationLabels = train_test_split ( trainData , trainLabels , test_size = 0.2 , random_state = 20 )
hist = model . fit_generator ( generator . flow ( trainData , trainLabels , batch_size = batch_size ),
steps_per_epoch = int ( len ( trainData ) / batch_size + 1 ),
epochs = 200 ,
verbose = 1 ,
validation_data = ( validationData , validationLabels ),
callbacks = [ TensorBoard ( log_dir = 'logs' ), checkpoint , TQDMNotebookCallback ( leave_inner = False , leave_outer = True )])
else :
hist = model . fit ( trainData , trainLabels , epochs = 50 , batch_size = batch_size ,
validation_split = 0.2 , callbacks = [ TensorBoard ( log_dir = 'logs' ), checkpoint , TQDMNotebookCallback ( leave_inner = False , leave_outer = True )], shuffle = True , verbose = 1 )
Train on 44596 samples, validate on 11149 samples
Epoch 1/50
44416/44596 [============================>.] - ETA: 0s - loss: 1.9518 - acc: 0.3241Epoch 00000: val_acc improved from -inf to 0.40721, saving model to lenet.best.h5
44596/44596 [==============================] - 15s - loss: 1.9505 - acc: 0.3242 - val_loss: 1.5514 - val_acc: 0.4072
Epoch 2/50
44416/44596 [============================>.] - ETA: 0s - loss: 1.4345 - acc: 0.4589Epoch 00001: val_acc improved from 0.40721 to 0.50839, saving model to lenet.best.h5
44596/44596 [==============================] - 12s - loss: 1.4342 - acc: 0.4588 - val_loss: 1.2875 - val_acc: 0.5084
Epoch 3/50
44416/44596 [============================>.] - ETA: 0s - loss: 1.2696 - acc: 0.5206Epoch 00002: val_acc improved from 0.50839 to 0.52893, saving model to lenet.best.h5
44596/44596 [==============================] - 12s - loss: 1.2698 - acc: 0.5206 - val_loss: 1.2496 - val_acc: 0.5289
Epoch 4/50
44416/44596 [============================>.] - ETA: 0s - loss: 1.1532 - acc: 0.5684Epoch 00003: val_acc improved from 0.52893 to 0.54382, saving model to lenet.best.h5
44596/44596 [==============================] - 12s - loss: 1.1534 - acc: 0.5681 - val_loss: 1.2182 - val_acc: 0.5438
Epoch 5/50
44416/44596 [============================>.] - ETA: 0s - loss: 1.0540 - acc: 0.6051Epoch 00004: val_acc improved from 0.54382 to 0.59611, saving model to lenet.best.h5
44596/44596 [==============================] - 12s - loss: 1.0538 - acc: 0.6053 - val_loss: 1.0992 - val_acc: 0.5961
Epoch 6/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.9640 - acc: 0.6407Epoch 00005: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.9643 - acc: 0.6407 - val_loss: 1.0834 - val_acc: 0.5935
Epoch 7/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.8681 - acc: 0.6772Epoch 00006: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.8681 - acc: 0.6772 - val_loss: 1.1228 - val_acc: 0.5957
Epoch 8/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.7734 - acc: 0.7133Epoch 00007: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.7736 - acc: 0.7134 - val_loss: 1.1125 - val_acc: 0.5957
Epoch 9/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.6917 - acc: 0.7451Epoch 00008: val_acc improved from 0.59611 to 0.63351, saving model to lenet.best.h5
44596/44596 [==============================] - 12s - loss: 0.6914 - acc: 0.7453 - val_loss: 1.0098 - val_acc: 0.6335
Epoch 10/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.5963 - acc: 0.7802Epoch 00009: val_acc improved from 0.63351 to 0.64867, saving model to lenet.best.h5
44596/44596 [==============================] - 12s - loss: 0.5964 - acc: 0.7802 - val_loss: 1.0253 - val_acc: 0.6487
Epoch 11/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.5171 - acc: 0.8149Epoch 00010: val_acc improved from 0.64867 to 0.65028, saving model to lenet.best.h5
44596/44596 [==============================] - 12s - loss: 0.5172 - acc: 0.8149 - val_loss: 1.1233 - val_acc: 0.6503
Epoch 12/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.4474 - acc: 0.8366Epoch 00011: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.4480 - acc: 0.8363 - val_loss: 1.1432 - val_acc: 0.6494
Epoch 13/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.3926 - acc: 0.8588Epoch 00012: val_acc improved from 0.65028 to 0.65495, saving model to lenet.best.h5
44596/44596 [==============================] - 12s - loss: 0.3929 - acc: 0.8588 - val_loss: 1.2312 - val_acc: 0.6549
Epoch 14/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.3358 - acc: 0.8813Epoch 00013: val_acc improved from 0.65495 to 0.67898, saving model to lenet.best.h5
44596/44596 [==============================] - 12s - loss: 0.3358 - acc: 0.8812 - val_loss: 1.1770 - val_acc: 0.6790
Epoch 15/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.2964 - acc: 0.8938Epoch 00014: val_acc improved from 0.67898 to 0.68374, saving model to lenet.best.h5
44596/44596 [==============================] - 12s - loss: 0.2965 - acc: 0.8937 - val_loss: 1.1827 - val_acc: 0.6837
Epoch 16/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.2570 - acc: 0.9102Epoch 00015: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.2577 - acc: 0.9100 - val_loss: 1.2213 - val_acc: 0.6818
Epoch 17/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.2346 - acc: 0.9164Epoch 00016: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.2346 - acc: 0.9164 - val_loss: 1.3509 - val_acc: 0.6771
Epoch 18/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.2004 - acc: 0.9302Epoch 00017: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.2009 - acc: 0.9300 - val_loss: 1.4450 - val_acc: 0.6723
Epoch 19/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.2001 - acc: 0.9320Epoch 00018: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.2003 - acc: 0.9319 - val_loss: 1.4628 - val_acc: 0.6534
Epoch 20/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.1791 - acc: 0.9380Epoch 00019: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.1792 - acc: 0.9380 - val_loss: 1.5870 - val_acc: 0.6588
Epoch 21/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.1673 - acc: 0.9429Epoch 00020: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.1674 - acc: 0.9428 - val_loss: 1.4457 - val_acc: 0.6828
Epoch 22/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.1529 - acc: 0.9486Epoch 00021: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.1532 - acc: 0.9485 - val_loss: 1.5998 - val_acc: 0.6637
Epoch 23/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.1549 - acc: 0.9471Epoch 00022: val_acc improved from 0.68374 to 0.68598, saving model to lenet.best.h5
44596/44596 [==============================] - 12s - loss: 0.1553 - acc: 0.9470 - val_loss: 1.4641 - val_acc: 0.6860
Epoch 24/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.1348 - acc: 0.9528Epoch 00023: val_acc improved from 0.68598 to 0.69217, saving model to lenet.best.h5
44596/44596 [==============================] - 12s - loss: 0.1352 - acc: 0.9527 - val_loss: 1.5187 - val_acc: 0.6922
Epoch 25/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.1390 - acc: 0.9526Epoch 00024: val_acc improved from 0.69217 to 0.69800, saving model to lenet.best.h5
44596/44596 [==============================] - 12s - loss: 0.1390 - acc: 0.9526 - val_loss: 1.4085 - val_acc: 0.6980
Epoch 26/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.1165 - acc: 0.9601Epoch 00025: val_acc improved from 0.69800 to 0.69890, saving model to lenet.best.h5
44596/44596 [==============================] - 13s - loss: 0.1168 - acc: 0.9600 - val_loss: 1.4850 - val_acc: 0.6989
Epoch 27/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.1232 - acc: 0.9590Epoch 00026: val_acc did not improve
44596/44596 [==============================] - 13s - loss: 0.1232 - acc: 0.9590 - val_loss: 1.5711 - val_acc: 0.6868
Epoch 28/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.1212 - acc: 0.9590Epoch 00027: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.1213 - acc: 0.9589 - val_loss: 1.5543 - val_acc: 0.6984
Epoch 29/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.1165 - acc: 0.9617Epoch 00028: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.1167 - acc: 0.9615 - val_loss: 1.5921 - val_acc: 0.6944
Epoch 30/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.1168 - acc: 0.9604Epoch 00029: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.1168 - acc: 0.9603 - val_loss: 1.6970 - val_acc: 0.6948
Epoch 31/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.1058 - acc: 0.9649Epoch 00030: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.1059 - acc: 0.9648 - val_loss: 1.5778 - val_acc: 0.6948
Epoch 32/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.1068 - acc: 0.9646Epoch 00031: val_acc improved from 0.69890 to 0.69988, saving model to lenet.best.h5
44596/44596 [==============================] - 12s - loss: 0.1068 - acc: 0.9645 - val_loss: 1.6127 - val_acc: 0.6999
Epoch 33/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.0994 - acc: 0.9668Epoch 00032: val_acc improved from 0.69988 to 0.70392, saving model to lenet.best.h5
44596/44596 [==============================] - 12s - loss: 0.0994 - acc: 0.9668 - val_loss: 1.5763 - val_acc: 0.7039
Epoch 34/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.0938 - acc: 0.9686Epoch 00033: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.0936 - acc: 0.9686 - val_loss: 1.6673 - val_acc: 0.6997
Epoch 35/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.0896 - acc: 0.9706Epoch 00034: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.0895 - acc: 0.9706 - val_loss: 1.7275 - val_acc: 0.6935
Epoch 36/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.0902 - acc: 0.9693Epoch 00035: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.0904 - acc: 0.9692 - val_loss: 1.6791 - val_acc: 0.6906
Epoch 37/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.0914 - acc: 0.9693Epoch 00036: val_acc improved from 0.70392 to 0.70544, saving model to lenet.best.h5
44596/44596 [==============================] - 12s - loss: 0.0914 - acc: 0.9693 - val_loss: 1.6200 - val_acc: 0.7054
Epoch 38/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.0884 - acc: 0.9711Epoch 00037: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.0885 - acc: 0.9711 - val_loss: 1.6909 - val_acc: 0.6976
Epoch 39/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.0832 - acc: 0.9725Epoch 00038: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.0832 - acc: 0.9725 - val_loss: 1.7651 - val_acc: 0.6984
Epoch 40/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.0817 - acc: 0.9735Epoch 00039: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.0817 - acc: 0.9735 - val_loss: 1.6548 - val_acc: 0.7039
Epoch 41/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.0873 - acc: 0.9716Epoch 00040: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.0875 - acc: 0.9715 - val_loss: 1.6279 - val_acc: 0.6946
Epoch 42/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.0782 - acc: 0.9746Epoch 00041: val_acc improved from 0.70544 to 0.70993, saving model to lenet.best.h5
44596/44596 [==============================] - 13s - loss: 0.0782 - acc: 0.9746 - val_loss: 1.7445 - val_acc: 0.7099
Epoch 43/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.0788 - acc: 0.9739Epoch 00042: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.0788 - acc: 0.9739 - val_loss: 1.6922 - val_acc: 0.6909
Epoch 44/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.0818 - acc: 0.9727Epoch 00043: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.0818 - acc: 0.9726 - val_loss: 1.7579 - val_acc: 0.6906
Epoch 45/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.0769 - acc: 0.9754Epoch 00044: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.0770 - acc: 0.9754 - val_loss: 1.7807 - val_acc: 0.6889
Epoch 46/50
44544/44596 [============================>.] - ETA: 0s - loss: 0.0755 - acc: 0.9754Epoch 00045: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.0755 - acc: 0.9754 - val_loss: 1.7862 - val_acc: 0.7039
Epoch 47/50
44544/44596 [============================>.] - ETA: 0s - loss: 0.0627 - acc: 0.9792Epoch 00046: val_acc improved from 0.70993 to 0.71361, saving model to lenet.best.h5
44596/44596 [==============================] - 12s - loss: 0.0629 - acc: 0.9791 - val_loss: 1.7728 - val_acc: 0.7136
Epoch 48/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.0733 - acc: 0.9770Epoch 00047: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.0734 - acc: 0.9770 - val_loss: 1.8777 - val_acc: 0.6930
Epoch 49/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.0732 - acc: 0.9760Epoch 00048: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.0732 - acc: 0.9759 - val_loss: 1.8457 - val_acc: 0.7033
Epoch 50/50
44416/44596 [============================>.] - ETA: 0s - loss: 0.0714 - acc: 0.9766Epoch 00049: val_acc did not improve
44596/44596 [==============================] - 12s - loss: 0.0716 - acc: 0.9765 - val_loss: 1.7901 - val_acc: 0.6812
from keras.models import load_model
model = load_model ( 'lenet.best.h5' )
y_prob = model . predict ( testData , batch_size = 32 , verbose = 0 )
y_pred = [ np . argmax ( prob ) for prob in y_prob ]
y_true = [ np . argmax ( true ) for true in testLabels ]
output = open ( 'prediction.csv' , 'w' )
for p in y_pred :
output . write ( str ( p ))
output . write ( " \n " )
output . close ()
def plot_subjects ( start , end , y_pred , y_true , title = False ):
fig = plt . figure ( figsize = ( 12 , 12 ))
emotion = { 0 : 'Angry' , 1 : "Disgust" , 2 : 'Fear' , 3 : 'Happy' , 4 : 'Sad' , 5 : 'Surprise' , 6 : 'Neutral' }
for i in range ( start , end + 1 ):
input_img = testData [ i :( i + 1 ),:,:,:]
input_img = np . reshape ( input_img , ( 48 , 48 ))
ax = fig . add_subplot ( 6 , 6 , i + 1 )
ax . imshow ( input_img , cmap = matplotlib . cm . gray )
plt . xticks ( np . array ([]))
plt . yticks ( np . array ([]))
if y_pred [ i ] != y_true [ i ]:
plt . xlabel ( "P: " + emotion [ y_pred [ i ]] + " A: " + emotion [ y_true [ i ]], color = '#53b3cb' , fontsize = 10 )
else :
plt . xlabel ( "P: " + emotion [ y_pred [ i ]] + " A: " + emotion [ y_true [ i ]], fontsize = 10 )
if title :
plt . title ( emotion [ y_pred [ i ]], color = 'blue' )
plt . tight_layout ()
plt . show ()
def plot_probs ( start , end , y_prob ):
fig = plt . figure ( figsize = ( 12 , 12 ))
color_set = ( '.00' , '.25' , '.50' , '.75' )
for i in range ( start , end + 1 ):
ax = fig . add_subplot ( 6 , 6 , i + 1 )
# color_list = [color_set[(len(color_set) * int(val * 100)) // 100] for val in y_prob[i]]
ax . bar ( np . arange ( 0 , 7 ), y_prob [ i ], alpha = 0.5 )
ax . set_xticks ( np . arange ( 0.5 , 7.5 , 1 ))
labels = [ 'angry' , 'disgust' , 'fear' , 'happy' , 'sad' , 'surprise' , 'neutral' ]
ax . set_xticklabels ( labels , rotation = 90 , fontsize = 10 )
ax . set_yticks ( np . arange ( 0.0 , 1.1 , 0.5 ))
plt . tight_layout ()
plt . show ()
def plot_subjects_with_probs ( start , end , y_prob ):
iter = ( end - start ) // 7
for i in np . arange ( 0 , iter ):
plot_subjects ( i * 6 ,( i + 1 ) * 6 - 1 , y_pred , y_true , title = False )
plot_probs ( i * 6 ,( i + 1 ) * 6 - 1 , y_prob )
plot_subjects_with_probs ( 0 , 36 , y_prob )
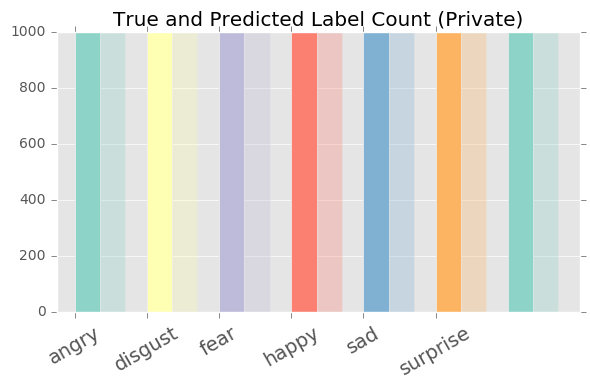
Plot the distribution of Predicted vs True
labels = [ 'angry' , 'disgust' , 'fear' , 'happy' , 'sad' , 'surprise' , 'neutral' ]
def plot_distribution ( y_true , y_pred ):
ind = np . arange ( 1.5 , 8 , 1 ) # the x locations for the groups
width = 0.35
fig , ax = plt . subplots ()
true = ax . bar ( ind , np . bincount ( y_true ), width , color = set3 , alpha = 1.0 )
pred = ax . bar ( ind + width , np . bincount ( y_pred ), width , color = set3 , alpha = 0.3 )
ax . set_xticks ( np . arange ( 1.5 , 7 , 1 ))
ax . set_xticklabels ( labels , rotation = 30 , fontsize = 14 )
ax . set_xlim ([ 1.25 , 8.5 ])
ax . set_ylim ([ 0 , 1000 ])
ax . set_title ( 'True and Predicted Label Count (Private)' )
plt . tight_layout ()
plt . show ()
plot_distribution ( y_true , y_pred )
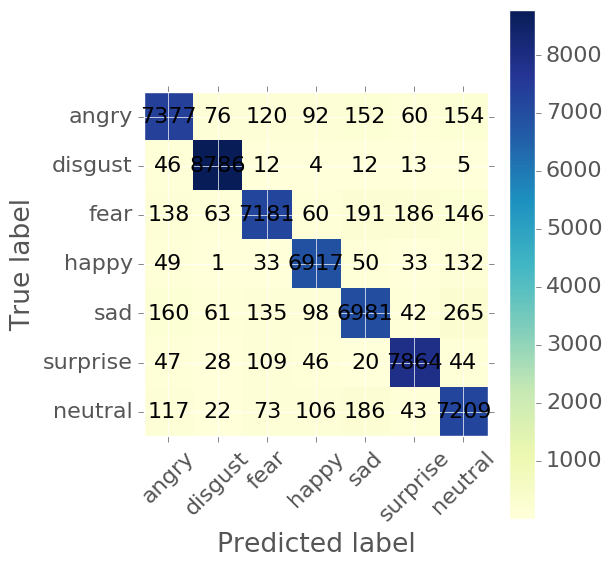
Confusion Matrix
from sklearn.metrics import confusion_matrix
def plot_confusion_matrix ( y_true , y_pred , cmap = plt . cm . Blues ):
cm = confusion_matrix ( y_true , y_pred )
fig = plt . figure ( figsize = ( 6 , 6 ))
matplotlib . rcParams . update ({ 'font.size' : 16 })
ax = fig . add_subplot ( 111 )
matrix = ax . imshow ( cm , interpolation = 'nearest' , cmap = cmap )
fig . colorbar ( matrix )
for i in range ( 0 , 7 ):
for j in range ( 0 , 7 ):
ax . text ( j , i , cm [ i , j ], va = 'center' , ha = 'center' )
# ax.set_title('Confusion Matrix')
ticks = np . arange ( len ( labels ))
ax . set_xticks ( ticks )
ax . set_xticklabels ( labels , rotation = 45 )
ax . set_yticks ( ticks )
ax . set_yticklabels ( labels )
plt . tight_layout ()
plt . ylabel ( 'True label' )
plt . xlabel ( 'Predicted label' )
plot_confusion_matrix ( y_true , y_pred , cmap = plt . cm . YlGnBu )
Classification Matrix
def class_precision ( y_true , y_pred , emotion ):
cm = confusion_matrix ( y_true , y_pred )
i = [ i for i , label in enumerate ( labels ) if label == emotion ][ 0 ]
col = [ cm [ j , i ] for j in range ( 0 , len ( labels ))]
return float ( col [ i ]) / sum ( col )
def class_recall ( y_true , y_pred , emotion ):
cm = confusion_matrix ( y_true , y_pred )
i = [ i for i , label in enumerate ( labels ) if label == emotion ][ 0 ]
row = [ cm [ i , j ] for j in range ( 0 , len ( labels ))]
return float ( row [ i ]) / sum ( row )
def class_accuracy ( y_true , y_pred , emotion ):
cm = confusion_matrix ( y_true , y_pred )
i = [ i for i , label in enumerate ( labels ) if label == emotion ][ 0 ]
tp = cm [ i , i ]
fn = sum ([ cm [ i , j ] for j in range ( 0 , 6 ) if j != i ])
fp = sum ([ cm [ j , i ] for j in range ( 0 , 6 ) if j != i ])
tn = sum ([ cm [ i , j ] for j in range ( 0 , 6 ) for i in range ( 0 , 6 )]) - ( tp + fp + fn )
return float ( tp + tn ) / sum ([ tp , fn , fp , tn ])
# private test set
for emotion in labels :
print ( emotion . upper ())
print ( ' acc = {}' . format ( class_accuracy ( y_true , y_pred , emotion )))
print ( ' prec = {}' . format ( class_precision ( y_true , y_pred , emotion )))
print ( 'recall = {} \n ' . format ( class_recall ( y_true , y_pred , emotion )))
ANGRY
acc = 0.9801028723832103
prec = 0.929795815477691
recall = 0.9185655584609638
DISGUST
acc = 0.9933111783756323
prec = 0.9722252960053115
recall = 0.9896373056994818
FEAR
acc = 0.9778379865800224
prec = 0.9371003523424246
recall = 0.9015693659761457
HAPPY
acc = 0.9901361048197617
prec = 0.9445582411579954
recall = 0.9586971586971587
SAD
acc = 0.9805050483669538
prec = 0.9195205479452054
recall = 0.901704985791785
SURPRISE
acc = 0.9876383802891434
prec = 0.9542531246207985
recall = 0.9639617553321893
NEUTRAL
acc = 0.9726308659483944
prec = 0.9062225015713388
recall = 0.9294739556472409
from sklearn.metrics import classification_report
print ( classification_report ( y_true , y_pred , target_names = labels ))
precision recall f1-score support
angry 0.93 0.92 0.92 8031
disgust 0.97 0.99 0.98 8878
fear 0.94 0.90 0.92 7965
happy 0.94 0.96 0.95 7215
sad 0.92 0.90 0.91 7742
surprise 0.95 0.96 0.96 8158
neutral 0.91 0.93 0.92 7756
avg / total 0.94 0.94 0.94 55745
Visualize the Keras Layers
# https://stackoverflow.com/questions/41711190/keras-how-to-get-the-output-of-each-layer
from keras import backend as K
def layers_overview ( images ):
total_rows = len ( images )
fig = plt . figure ( figsize = ( 8 , 10 ))
idx = 0
for i , row in df . iterrows ():
input_img = img
ax = fig . add_subplot ( 16 , 12 , idx + 1 )
ax . imshow ( input_img , cmap = matplotlib . cm . gray )
plt . xticks ( np . array ([]))
plt . yticks ( np . array ([]))
plt . tight_layout ()
idx += 1
plt . show ()
def get_layer_outputs ( img , use_dropout ):
test_image = img
outputs = [ layer . output for layer in model . layers ] # all layer outputs
comp_graph = [ K . function ([ model . input ] + [ K . learning_phase ()], [ output ]) for output in outputs ] # evaluation functions
# Testing
dropout = 1 if use_dropout else 0
layer_outputs_list = [ op ([ test_image , dropout ]) for op in comp_graph ]
layer_outputs = []
for layer_output in layer_outputs_list :
print ( layer_output [ 0 ][ 0 ] . shape , end = ' \n ------------------- \n ' )
layer_outputs . append ( layer_output [ 0 ][ 0 ])
return layer_outputs
def plot_layer_outputs ( img , layer_number , use_dropout ):
layer_outputs = get_layer_outputs ( img , use_dropout )
x_max = layer_outputs [ layer_number ] . shape [ 0 ]
y_max = layer_outputs [ layer_number ] . shape [ 1 ]
n = layer_outputs [ layer_number ] . shape [ 2 ]
L = []
for i in range ( n ):
L . append ( np . zeros (( x_max , y_max )))
for i in range ( n ):
for x in range ( x_max ):
for y in range ( y_max ):
L [ i ][ x ][ y ] = layer_outputs [ layer_number ][ x ][ y ][ i ]
# for img in L:
# plt.figure(figsize=(2, 2))
# plt.imshow(img, interpolation='nearest', cmap='gray')
layers_overview ( L )
test_img = [ testData [ 0 ]]
plot_layer_outputs ( np . array ( test_img ), 2 , use_dropout = False )
(46, 46, 64)
-------------------
(23, 23, 64)
-------------------
(23, 23, 64)
-------------------
(21, 21, 128)
-------------------
(10, 10, 128)
-------------------
(10, 10, 128)
-------------------
(8, 8, 256)
-------------------
(4, 4, 256)
-------------------
(4, 4, 256)
-------------------
(2, 2, 512)
-------------------
(1, 1, 512)
-------------------
(1, 1, 512)
-------------------
(1, 1, 512)
-------------------
(512,)
-------------------
(256,)
-------------------
(256,)
-------------------
(256,)
-------------------
(7,)
-------------------
(7,)
-------------------
Kaggle - Facial Expression Recognizer was published on June 15, 2017 and last modified on June 15, 2017 .